Service chaining is getting a lot of attention recently. What does it matter? Let’s look at a very simple example, illustrated below.
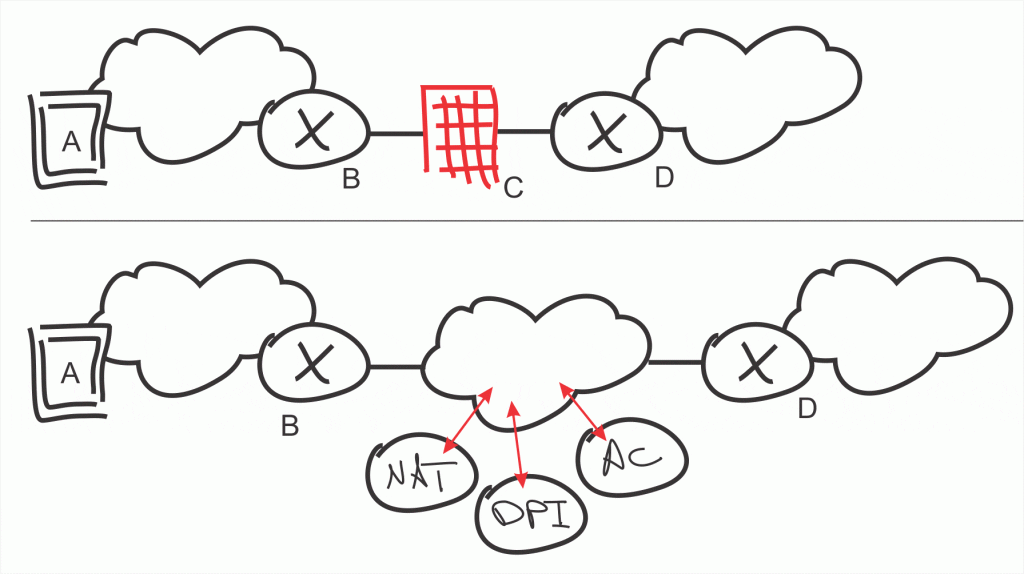
In the upper part of this image, a host (in this case a laptop, just for example), transmits a packet through the network towards a server located beyond D (see right side). This packet is carried through some edge network (MPLS, LTE, Internet VPN, etc.) and into the edge router at the carrier PE router, marked as B in the diagram. The carrier has a set of policies describing specific operations that must take place on the packet (or data stream) before it can be forwarded through D on its way to the ultimate destination. To implement these policies, the carrier puts an appliance in the path of the packet, such as a firewall — C in the diagram. This is all pretty simple — it’s fairly standard approach that we see in network design on an every day basis.
But let’s back up and consider what that appliance really does. A firewall provides a set of services, such as network address translation, deep packet inspection, and access control. What the network operator pays for is the hardware and software that performs each of these actions at wire speed — which is a complicated task. But why should these services be bundled into a single appliance in this way? Is there some “magic rule of networking,” that says all the policies implemented in a data stream must be contained on a single box, or even in a set of appliances? No, there’s not.
Let’s split these individual processes up, and put them on generic hardware. After all, we have a data center fabric sitting someplace with a ton of compute and storage; it’s easy enough to spin a VM that can perform CGNAT (Carrier Grade NAT), for instance. In fact, developing and deploying a set of applications that each, individually, perform one of these three functions — CGNAT, Deep Packet Inspection and Access Control — onto generic compute resources on a data center fabric is a pretty simple concept. Now if traffic that needs to be DPI’d increases, we can scale out (rather than scaling up) by just spinning a few more VMs.
You’ll quickly see the problem here… These processes aren’t in the path of the traffic flow I’m trying to apply the services to.
- How can I solve this? I can’t readily push each of these services into the shortest path between A and the destination, out between D.
- If I can’t bring the services to the packets, why not bring the packets to the services?
- What if I could, at A, determine the set of services through which this particular flow of packets must pass on its way towards the destination, past D?
- What if I could instruct A to stack as set of MPLS labels, for instance, onto the packet as it’s switched through A, so that it will be sent to each of the various service VMs in turn as it passes through the data center fabric, and before being passed to D to continue it’s journey to the actual destination?
This is precisely what service chaining actually does — in the case of the MPLS fabric, you could stack a set of labels onto the packet at the network ingress (at the data center border router, or the first leaf node the packet encounters, or even the edge of the network itself). The first label will actually cause the network to forward the traffic to the first service in the chain, which then pops its label and forwards the packet along. The second label causes the packet to be sent to the second service, which then pops the second label and forwards the packet along.
This is a simple, but powerful, idea. It allows you to virtualize services into a generic (and well understood) data center fabric, running the service on standard compute and storage. It allows us to insert and remove services easily. You can simply spin up VMs and push the right stack of labels at the network entrance. Finally, it allows us to scale services by spinning additional VMs, and using scale out rather than scale up principles.
Which leads the obvious question: what’s the cost? According to network complexity theory, there’s no such thing as a free lunch — all decisions are trade-offs, rather than absolute. What’s the trade-off here?
The most obvious one is the increased stretch through the network. Rather than passing through the network core (or data center fabric) once, packets have to find their way across the fabric once per service. If the cost of the network is cheaper than the cost of appliances plus the cost of rolling a truck (or installing new hardware) to roll out a new service, or add/remove a specific policy point for any given user, then service virtualization and chaining is a clear winner. If the cost of the network is high, however…
Other trade-offs to consider are the additional latency and delay through the network, the actual cost of generic hardware (if it takes ten blade servers to replicate a single appliance, is there a real gain?), and the additional complexity of (essentially) traffic engineering per flow. Which way the trade-offs fall out will all depend…
 Russ White has written many books, written a variety of patents, drafted RFCs. You can find his author page on Amazon. You can also find him on the Internet Protocol Journal, Linked-In and Packet Pushers.
Russ White has written many books, written a variety of patents, drafted RFCs. You can find his author page on Amazon. You can also find him on the Internet Protocol Journal, Linked-In and Packet Pushers.
